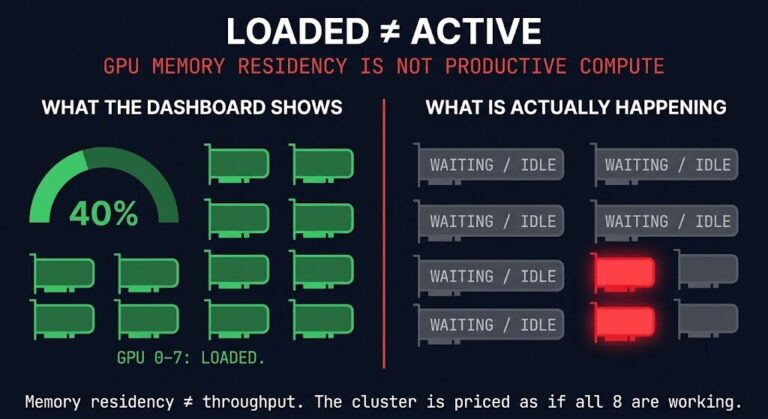
The Network Is Becoming the AI Control Plane
The industry thinks AI infrastructure is a GPU problem. It is actually an AI control plane problem — and the control plane is relocating into the network fabric. The more scheduling intelligence moves into that fabric layer, the less important the individual compute node becomes — and the more important the layer that determines where that node’s workload runs. Scheduling intelligence attracts authority. It always has, across every infrastructure era. The difference now is that the layer gaining intelligence is the network, and the decisions it is absorbing are runtime decisions for AI workloads — inference placement, agent communication routing, job-level congestion isolation, collective communication orchestration. These are not configuration parameters. They are operational decisions with organizational consequences.
AI Infrastructure Is Creating a New Control Surface
The decisions now embedded in the network fabric are not networking features. They are runtime decisions:
- Inference routing — which endpoint serves a given request based on fabric-layer state
- Agent communication paths — which routes agent-to-agent traffic takes through the infrastructure
- Model placement — where a workload lands, influenced by fabric topology and policy
- Fabric-aware scheduling — workload assignment decisions that incorporate network constraints as first-class inputs
- Traffic steering — how collective communication patterns are orchestrated across nodes
Each of these determines how an AI system behaves under load. Each carries operational authority. And each now lives, at least partially, in the network layer.
The distinction matters because networking and runtime operations are governed by different teams, different toolchains, and different organizational accountability structures. When runtime decisions migrate into a layer historically treated as infrastructure plumbing, the AI control plane question does not resolve itself automatically. It waits until something breaks.
DIAGNOSTIC QUESTION
“Who in your organization approves AI routing policy — and do they know what fabric-level decisions that approval covers?”
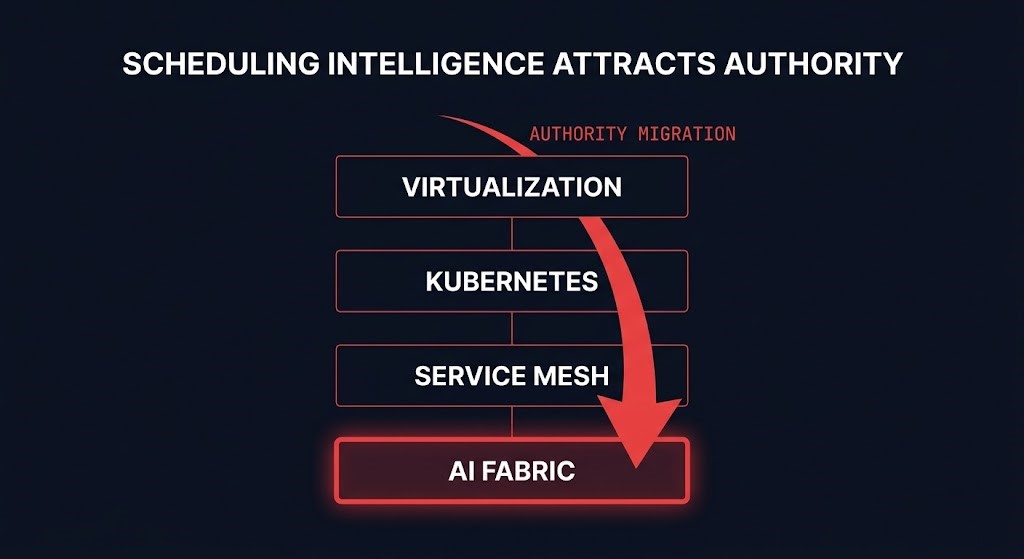
The Layer of Intelligence Has Always Moved Downward
This is not the first time scheduling intelligence has migrated to a lower infrastructure layer. The pattern is consistent across every major era of enterprise infrastructure:
| Era | Authority Moved To |
|---|---|
| Virtualization | Hypervisor Scheduler |
| Kubernetes | Cluster Scheduler |
| Service Mesh | Traffic Policy Layer |
| AI Infrastructure | Fabric Layer |
In the virtualization era, workload placement authority migrated into the hypervisor scheduler. Teams that had manually assigned workloads to physical hardware ceded that authority to vSphere DRS and equivalent schedulers. The intelligence was in the hypervisor; the authority followed. In the Kubernetes era, placement authority migrated again — from hypervisor schedulers into cluster schedulers. The service mesh era absorbed traffic policy: circuit breaking, retry behavior, identity enforcement, and routing logic moved from application code into the mesh layer. Whoever controlled mesh configuration controlled application behavior.
Each migration followed the same logic: the layer with the most scheduling intelligence became the layer with the most operational authority, regardless of what the org chart said. No era was designed this way. The transfers were an emergent consequence of where the intelligence was built. The control plane shift has been directionally consistent across a decade of infrastructure evolution — the fabric layer is the next destination.
Scheduling intelligence attracts authority explains every row in that table. It will explain the next row too.
Infrastructure Authority Migration — Framework #103
Infrastructure Authority Migration: The movement of operational decision-making authority from the layer that executes workloads to the layer that determines workload placement.
This framework describes a recurring structural transition in infrastructure history. The authority does not disappear when it migrates — it relocates to whatever layer has acquired the intelligence to make placement decisions. The organizational acknowledgment of that relocation routinely lags the technical reality by months or years.
For AI infrastructure, the relocation is already in progress. The fabric layer now holds inputs that directly determine inference latency, job completion time, GPU utilization, and agent communication fidelity. The teams deploying AI workloads did not design this arrangement. The vendors building AI-native fabrics did.
The important question is not architectural. It is organizational: Who owns the AI control plane when it lives inside the network fabric?
Inference routing is the clearest example of this migration in practice. What began as an application-layer concern — which endpoint handles a given inference request — is now shaped by fabric-layer state, congestion policy, and collective communication topology. The authority over inference behavior has moved, whether or not the teams responsible for that behavior have noticed. The AI control plane shadow IT pattern — where AI tools create authority vacuums autonomously — is the same structural problem from the opposite direction. In both cases, authority migrates without organizational design.
The shadow control plane pattern at the CI/CD layer demonstrates how these vacuums compound. When the layer with authority is not the layer with accountability, the gap between them becomes the failure surface. Infrastructure Authority Migration is the mechanism that creates those gaps.
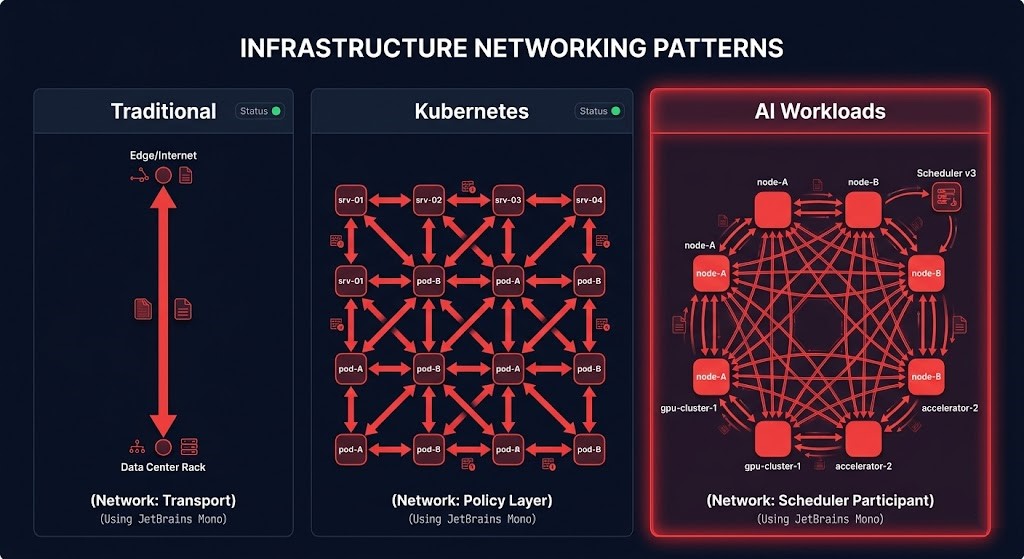
AI Workloads Behave Differently Than Traditional Infrastructure
To understand why the network layer now holds runtime authority for AI, the workload communication patterns need to be understood directly.
Traditional workloads are predominantly north-south. An application tier communicates with a database tier. The network is transport — it moves packets between defined endpoints. Latency matters, but topology is secondary. The network does not need to understand what the workload is doing to serve it.
Kubernetes workloads increased east-west traffic significantly. Service-to-service communication within a cluster became as important as external traffic. The network needed to become policy-aware — enforcing identity, managing retries, controlling circuit-breaking behavior. The service mesh emerged precisely because the network layer needed to participate in workload behavior, not just transport it.
AI workloads do not follow either pattern. Collective communication dominates: all-reduce operations during training, gradient synchronization across distributed nodes, parameter exchange between model shards, inference scatter-gather across serving replicas, agent-to-agent communication in multi-agent pipelines. These patterns are topology-sensitive, latency-intolerant, and parallelism-dependent. The network does not transport AI workloads. It participates in their execution.
The practical consequence: the network fabric now directly affects job completion time, placement efficiency, GPU utilization, and scheduling decisions. The physics of AI fabric communication — collective operation latency, congestion isolation between concurrent jobs, adaptive routing under asymmetric load — are not performance tuning concerns. They are architectural determinants of whether AI systems work at the expected scale.
This is the technical basis for Infrastructure Authority Migration at the fabric layer. The intelligence required to serve AI workloads well cannot live above the fabric. The layer that holds that intelligence will hold the authority.
The structured reading sequence for fabric topology, congestion control, and the Execution Locality Boundary lives in the Fabric Architecture stage of the AI Architecture Learning Path — the stage where these workload communication patterns translate into specific architectural decisions.
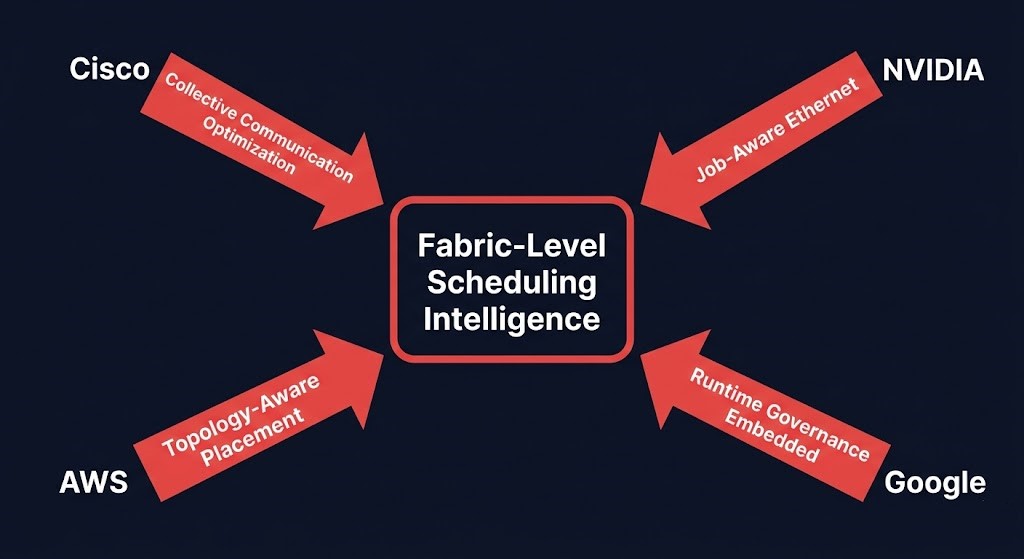
Why Cisco, AWS, Google, and NVIDIA Are Building the Same Thing
The convergence is visible in what every major infrastructure vendor shipped in the past six months. Different implementations, same architectural direction.
Cisco — AgenticOps + Silicon One G300 positions the network fabric as an active participant in AI job execution. The G300 delivers collective communication optimization at the hardware layer, with Intelligent Collective Networking designed to understand and optimize AI traffic patterns rather than treat them as undifferentiated bulk traffic. Cisco Live 2026 (May 31–June 4) makes this positioning explicit: the network layer is not adjacent to AI infrastructure. It is part of it.
NVIDIA — Spectrum-X implements job-aware Ethernet. Per-job congestion isolation, RoCE optimization, and adaptive routing that understands AI collective communication semantics at the hardware layer. The fabric becomes job-aware, not just topology-aware.
AWS — Elastic Fabric Adapter and UltraCluster topology-aware placement make fabric topology a first-class input to workload placement decisions. Where a workload lands in an AWS environment is inseparable from how the underlying fabric connects the nodes.
Google — The agent governance stack emerging from Google Cloud Next 2026 embeds network-layer routing policy and observability into the runtime governance model. Infrastructure governance is no longer a layer above the network. It runs inside it.
Four vendors, four implementations. One direction: distributed AI fabric intelligence is moving toward the network layer, not away from it. The convergence is not a trend. It is the natural architectural response to workload communication patterns that only the fabric layer can satisfy. The AI control plane is not being built above the network. It is being built into it.
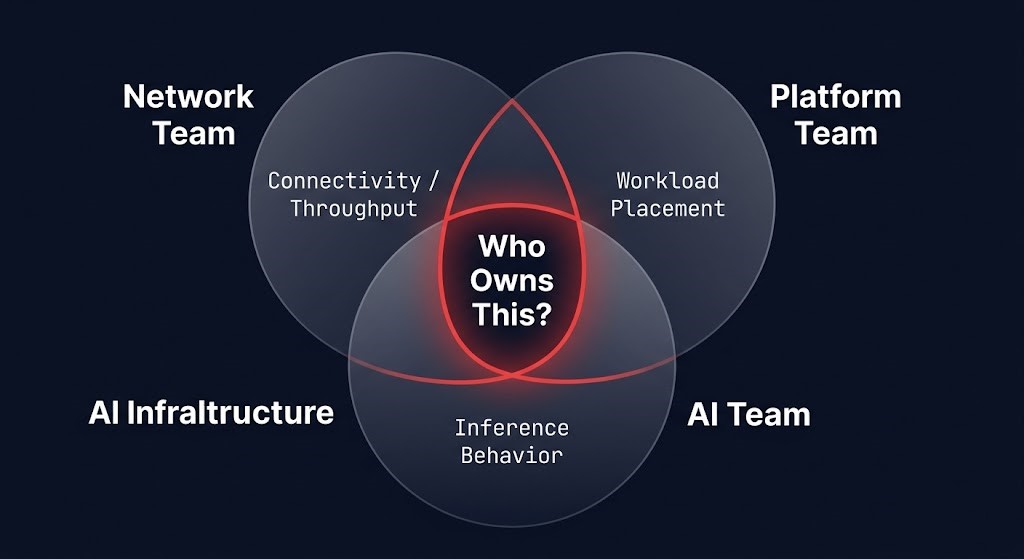
The Network Team Didn’t Ask For This
The authority transfer is not the result of a deliberate organizational decision. It is the byproduct of product releases.
Network teams have historically owned a defined operational domain: connectivity, packet loss, throughput, uptime. These are infrastructure health metrics. They do not carry workload authority — a network engineer is not responsible for whether a specific application performs correctly, only for whether the underlying transport is operating within parameters.
Vendors are now embedding a different set of capabilities into that same layer: placement logic, scheduling awareness, per-job congestion decisions, workload prioritization policies. These capabilities arrived through product specifications and hardware releases, not through organizational negotiation.
The result is a transfer nobody planned:
- Network teams inherit authority they never requested — accountability for decisions that affect AI workload outcomes
- Platform teams lose authority they never intended to surrender — placement and routing behavior that was previously under platform control
- AI teams are shipping workloads into fabric behavior they do not fully understand, because the fabric features that affect their outcomes are below their operational horizon
Most organizations have not noticed the transfer. The org chart shows three separate teams with clean ownership boundaries. The infrastructure shows one layer — now functioning as the AI control plane — making decisions that cross all three. The gap between those two pictures is where governance failures originate — and where incident post-mortems eventually point.t.
⚠ COMMON MISTAKE
Most enterprises are running AI workloads on fabric that has more scheduling intelligence than anyone in their organization was asked to govern. The org chart shows clean ownership boundaries. The infrastructure does not.
The Governance Problem Comes Next
Most organizations still think AI governance is about approving models. The next generation of AI governance will be about approving infrastructure behavior.
The current governance model was designed for a specific question: which model was approved? Model approval workflows, security reviews, compliance policies, and data access controls address that question adequately. They do not address the question that Infrastructure Authority Migration creates.
The next governance challenge is infrastructure governance. The question is no longer which model was approved. The question is who controls the fabric-level decisions that determine where, when, and how that model executes — inference routing, agent communication paths, placement constraints, congestion policy, workload prioritization. These decisions affect compliance outcomes, cost outcomes, and reliability outcomes. None of them appear in a model approval workflow.
Who approves AI routing policy? Who sets fabric scheduling constraints when they conflict with platform policy? Who is accountable when a scheduling decision made at the fabric layer produces a latency violation at the application layer? Who owns the placement constraint when a governance requirement mandates that inference for a specific workload never crosses a geographic boundary? Most enterprises have no answer — not because nobody thought to ask, but because the infrastructure shipped before the governance model was designed. The architectural consequences of that gap are most visible in environments where the AI control plane spans multiple regions without a resilience model — the conditions that produce a single-region AI control plane failure domain are the same conditions that make fabric-level governance debt operationally expensive.
The architectural stage where that governance model is built — who holds execution authority, how policy enforcement is defined across the control plane, and what Runtime Authority Vacuum looks like when fabric-level scheduling intelligence has no defined organizational owner — is Governance & Runtime Control (A6) in the AI Infrastructure Architecture Path.
The governance model also cannot be designed in isolation from infrastructure readiness. Autonomous operations require observable, governed, and recoverable infrastructure as a precondition — the same maturity requirements that fabric-level AI governance depends on. An organization that hasn’t satisfied those prerequisites cannot govern fabric-level scheduling decisions, regardless of which team owns the policy model. The specific infrastructure maturity conditions required before fabric-level governance can be operationally enforced — observable state, defined recovery paths, and governed execution surfaces — are the subject of Autonomous Operations Require Infrastructure Most Enterprises Don’t Have.
The sovereign networking and control plane isolation problem makes this even sharper: when regulatory requirements mandate control plane isolation, the governance model must extend into the fabric layer. There is no compliant implementation that treats the fabric as outside the governance boundary once that layer is making placement decisions.
DIAGNOSTIC QUESTION
“Can you name the person in your organization accountable for fabric-level AI scheduling policy — and can they tell you what that policy currently is?”
Each infrastructure refresh cycle embeds more scheduling intelligence into more fabric features. Each cycle that passes without resolving the authority question compounds the governance debt. The debt is not theoretical. It shows up in post-mortems, compliance gaps, and performance failures that trace back to decisions made in a layer nobody was assigned to govern.
Architect’s Verdict
The GPU was never going to stay at the center of the AI control plane authority model. Every infrastructure era has followed the same pattern: the layer that gains scheduling intelligence gains operational authority, regardless of what the org chart says. That layer is now the network fabric. Cisco, NVIDIA, AWS, and Google are not converging by accident. They are responding to workload communication requirements that only the fabric layer can satisfy — and building intelligence into that layer that will carry authority whether or not anyone designs for it.
Scheduling intelligence attracts authority. The organizations that understand this are not trying to stop the migration. They are designing the governance model for where authority is going — defining ownership, accountability, and policy approval before the next infrastructure refresh embeds more intelligence into the fabric and the question becomes harder to answer.
The architects who get ahead of this are not the ones who know the Silicon One G300 feature set. They are the ones who can answer, today, who owns the decisions that feature set is now making.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session