GPU Allocation Governance Is the Next AI Infrastructure Crisis
GPU allocation governance is becoming the defining AI infrastructure challenge of 2026 — not because enterprises cannot acquire GPUs, but because they cannot arbitrate who uses them.
The GPU Shortage Didn’t End. It Changed Shape.
By May 2026, VentureBeat’s AI Infrastructure tracker showed “access to GPUs” dropping from the #1 enterprise concern (20.8% of decision-makers) to #4 (15.4%) in a single quarter. Meanwhile, “cost per inference” and “total cost of ownership” surged from #3 to #1 in the same window.
The procurement problem that defined 2024 and early 2025 — lead times of 36–52 weeks, hyperscalers with two years of output reserved, smaller organizations paying premium rates for overflow capacity — is still real. But it stopped being the problem.
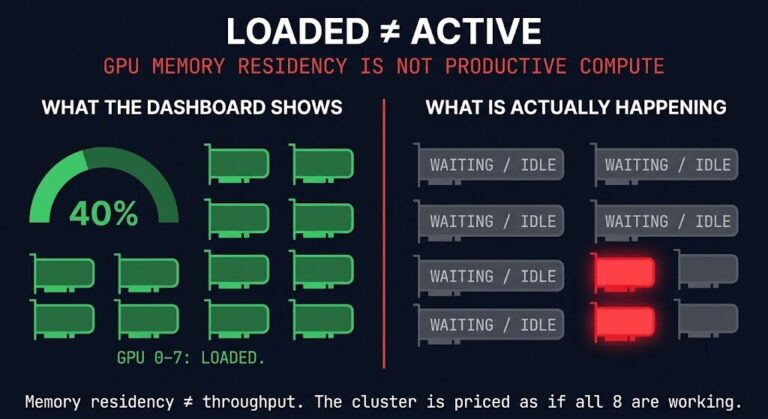
Organizations that spent $50M on GPU clusters discovered something uncomfortable: 95% of that capacity sits dark when usage-based billing starts. Not because they can’t buy GPUs. Because they can’t coordinate workloads on the same cluster.
The GPU shortage didn’t disappear. It moved up the stack.
Why GPU Capacity Sits Idle on Busy Clusters
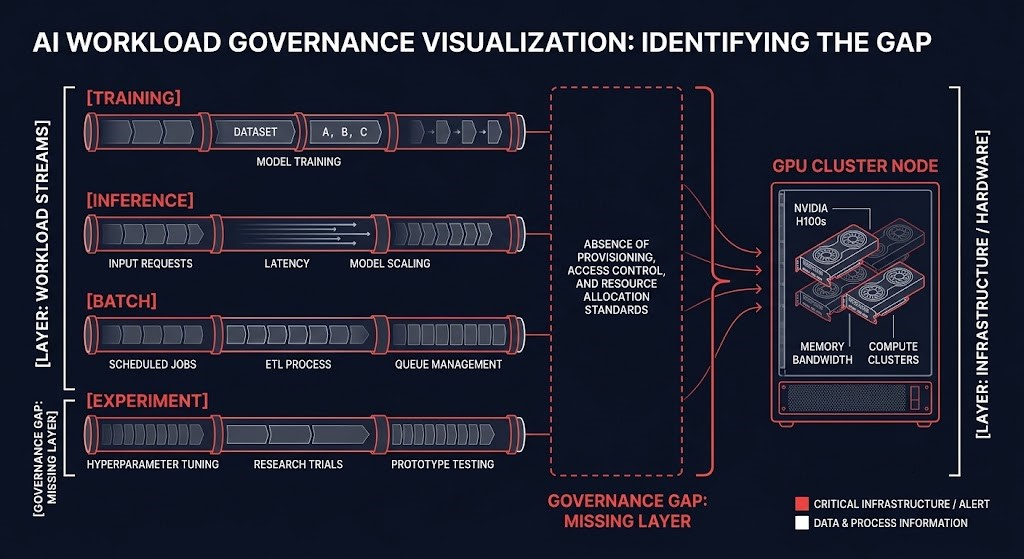
GPU clusters increasingly host four fundamentally different workload classes. Each optimizes for a different outcome, which means capacity that appears available to one workload may be unusable for another.
| Workload Class | Optimization Target |
|---|---|
| Training | Throughput |
| Inference | Latency |
| Batch Analytics | Cost |
| Experimentation | Flexibility |
A cluster optimized for training throughput — sustained GPU memory and high-bandwidth interconnects held for 72-hour jobs — becomes structurally inefficient the moment inference workloads need guaranteed low-latency access on the same hardware. Batch jobs want whatever is available right now and will queue if it isn’t. Experimentation runs for four hours and evaporates, but it contends for the same reserved blocks.
Put all four on the same cluster with static resource allocation — which is what most organizations do — and the math collapses. Training gets a reserved block. It runs at 70% utilization when actually scheduled, sits idle between jobs. Inference gets its own GPU allocation; during off-peak hours, that GPU is dark. Batch jobs queue because both training and inference have reserved capacity. Experiments run on whatever’s left.
Static partitioning on mixed workloads wastes 40–60% of capacity even when the cluster is busy.
And then there is a fifth workload class that compounds the problem. The highest-priority workload is rarely the most efficient one. Executive-sponsored AI initiatives often receive guaranteed access to GPU resources regardless of utilization characteristics, introducing political prioritization into what appears to be a technical allocation problem. That capacity cannot be denied, cannot be reclaimed during idle windows, and does not appear in any utilization dashboard as waste. It is simply reserved.
The cluster dashboard says 82% allocated. The infrastructure team believes capacity is exhausted. The data science team is requesting another GPU purchase. Finance sees tens of millions in idle CapEx. All three are reading the same cluster and reaching different conclusions — because allocation and utilization are not the same metric.

The Allocation Layer Nobody Planned For
Every organization eventually discovers that GPU allocation is an authority problem before it becomes a scheduling problem.
This is the part of AI infrastructure architecture that most platform teams reach without a plan. The acquisition phase has a clear owner: procurement. The deployment phase has a clear owner: infrastructure. The runtime phase has a clear owner: platform engineering.
Allocation governance has no natural owner.
Infrastructure teams own clusters. Data science teams own model workloads. Platform teams own deployment pipelines. Finance owns the CapEx budget. Each group optimizes locally: infrastructure maximizes hardware uptime, data science maximizes experiment throughput, platform maximizes deployment velocity, finance minimizes spend.
Nobody governs globally. More importantly, nobody has the authority to deny requests when demand exceeds capacity. Anyone can approve a GPU allocation request. Very few teams are empowered to refuse one. That is where allocation actually breaks — not in the scheduler, not in the manifest, but in the absence of any declared authority to arbitrate competing demand.
The result is predictable: workloads compete implicitly, utilization degrades quietly, and every team blames a different part of the stack. Infrastructure orders more hardware. Data science queues more jobs. Finance approves more spend. The allocation problem compounds behind a utilization number that looks healthy until you separate allocation from actual work.
This pattern has direct precedent in the Persistent Inference Residency Stack (Framework #2), which defines where inference workloads live and why they carry a fundamentally different cost model than training. Framework #3 (Inference Residency Creep, same post) shows how that footprint expands over time as more workloads converge on shared models. This post identifies what happens at the layer above: when multiple persistent residents compete for finite GPU inventory simultaneously, allocation becomes the governing problem — and the governance layer was never built.
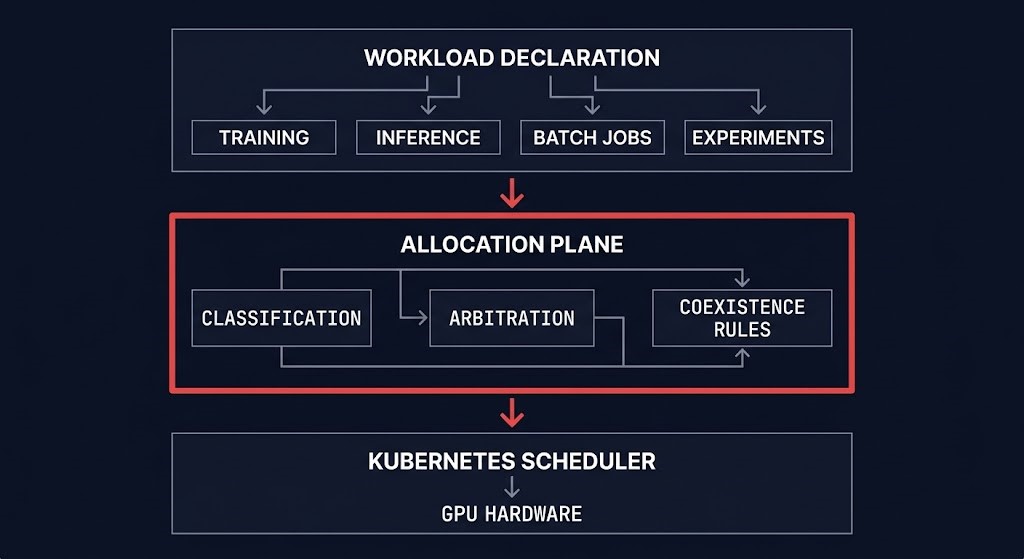
Organizations building allocation governance are doing four things that most are not: classifying workloads explicitly before scheduling rather than inferring workload type from resource requests; defining placement coexistence rules that specify which workload classes can share hardware without interference; establishing request arbitration — who can ask for capacity, what happens when demand exceeds supply, and crucially, who is authorized to say no; and closing utilization feedback loops so the allocation layer learns from actual GPU consumption rather than declared reservations.
This layer lives above Kubernetes. It is not a Kubernetes extension and cannot be built inside Kubernetes configuration alone.
GPU Allocation Governance: Kubernetes Cannot Solve This Alone
Kubernetes is behaving exactly as designed. The failure occurs because organizations are asking a scheduler to perform a governance function.
Kubernetes’ scheduler understands CPU requests and limits, memory pressure, node topology, and pod affinity. It does not understand model memory footprint — an H100 with 80GB can fit a 70B parameter model but not a 200B parameter one. It does not understand KV cache pressure, which consumes memory nonlinearly with sequence length under real inference load. It does not understand MIG slice compatibility, inference latency targets, or GPU memory fragmentation.
When Kubernetes places a pod, it sees “GPU: 1” as a resource unit. What it is actually placing is a workload with unknown memory behavior, unpredictable access patterns, and failure modes the scheduler has no visibility into.
The concrete result: the scheduler marks a node as “available: 40GB.” The workload needs 32GB. The pod is placed. It runs for 30 seconds, then fails — because GPU memory fragmentation means 40GB available is not 32GB contiguous. Kubernetes marks the pod as failed and reschedules it to the same node. The infrastructure team opens a ticket. The data science team re-queues the job. Nobody connects it to a missing allocation layer.
Kubernetes has no model for gpu allocation governance — because allocation governance was never in its design scope. Solving the utilization problem inside Kubernetes configuration is the wrong intervention at the wrong layer. The scheduler can only enforce what the allocation layer has already decided. If the allocation layer doesn’t exist, the scheduler is making governance decisions it was never designed to make.
This is directly related to the fragmentation patterns described in GPU Scheduling in Kubernetes: Start Before the Scheduler — the pre-scheduler decisions that determine whether workloads can coexist at all.
Architect’s Verdict
If your organization has $50M in GPU CapEx running at 5% utilization, the problem is not Nvidia. The problem is not your cluster size. The problem is that nobody has declared who is allowed to use what, when, and under what constraints — and nobody has the authority to enforce that declaration against competing demand. That is not a Kubernetes configuration problem. That is an architecture decision.
The industry solved access. It has not solved allocation.
The first phase of AI infrastructure was getting access to GPUs. The next phase is deciding which workloads deserve them. The organizations that build allocation governance will extract value from existing capacity. The organizations that don’t will keep buying hardware to compensate for architectural ambiguity.
The next phase of AI infrastructure isn’t GPU acquisition. It’s GPU arbitration.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session