Configuration Drift Is the Symptom. Ownership Is the Problem.

Configuration drift is treated as a visibility problem solved by tooling. It isn’t. Configuration drift ownership is the real breakdown — accountability over declared infrastructure state — and no detection pipeline closes that gap.
The industry built a full tooling category around drift: scanners, policy-as-code engines, GitOps reconciliation loops, IaC state management. Engineers get alerted when state diverges. Pipelines remediate. Tickets close. The problem is that none of those actions assign ownership. The loop runs cleanly at the boundary it was designed for. It is insufficient at the layer where accountability actually breaks.
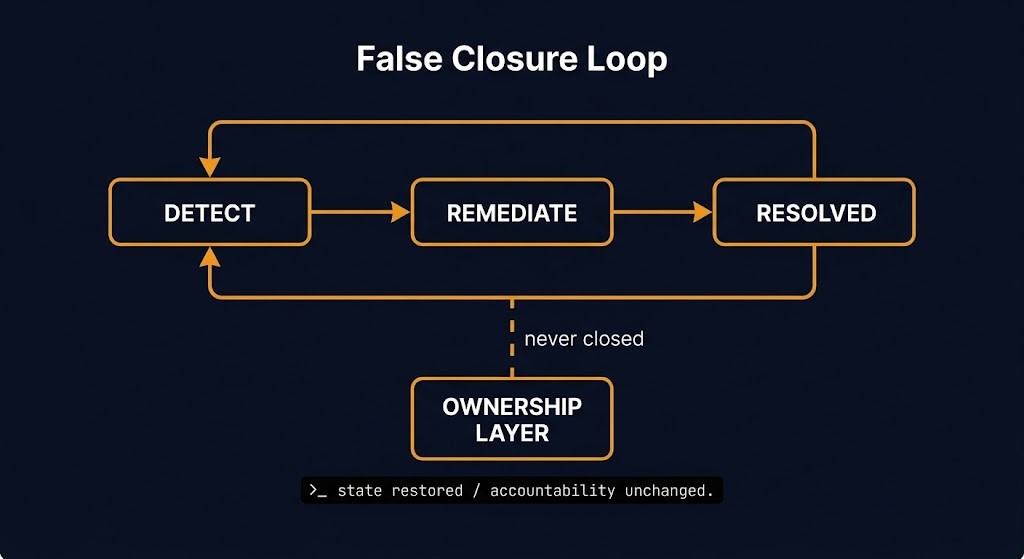
How the Industry Closes the Loop on Paper
The canonical model goes: declare state in code, detect divergence, trigger remediation, mark resolved. Every tool in the drift management category is optimized for this cycle. Each one is correct within its designed boundary.
What the model doesn’t close is the accountability layer underneath it. Detection fires, remediation executes, the alert clears — and the authority vacuum that permitted the deviation remains completely intact. The state returns to declared. The ownership question was never asked.
This is the false closure loop. The system resolves the symptom on every cycle. The condition that produces the symptom is structurally untouched.
Most teams running mature IaC pipelines know this intuitively. Drift events recur at the same resources. The same exceptions accumulate in the same environments. The tooling is working exactly as designed. The problem isn’t the tooling.
Related: IaC Drift Detection: Design for Detection, Not Prevention — how the detection boundary was scoped and why it stops where it does.
Drift Does Not Begin With a Configuration Change
Drift does not begin with a configuration change. It begins with ambiguity in who is allowed to define truth.
These conditions rarely appear simultaneously. They accumulate as systems scale and responsibilities diffuse — what starts as a clean ownership model erodes gradually until the erosion becomes the environment’s normal operating state. By the time drift is visible, the ownership model has usually been degraded for months.
Related: State & Dependency Architecture — the erosion this section describes is a single instance of a broader pattern: ownership dilution as infrastructure matures into a platform. The Learning Path stage maps how that dilution compounds across dependency, state, and lifecycle — not just drift.
This ownership collapse has a downstream expression that runs entirely inside a clean GitOps pipeline: when a policy’s original justification expires but enforcement continues unreviewed, the configuration never drifts — the intent behind it does. Policy Intent Drift is what the ownership gap looks like once the state itself has stopped moving.
The escalation follows a predictable sequence:
Ambiguous authority boundaries. Two teams hold overlapping write authority over the same resource. Neither is violating policy. Neither is accountable. When the resource deviates from declared state, there is no single party whose job it is to resolve the discrepancy — so it persists.
Related: GitOps Has Escaped The Platform Team — Framework #165 Authority Arbitration Gap: the reconciliation-loop-scale version of this exact sentence, where two or more GitOps loops hold overlapping authority over the same cluster resource, each correctly owned, with nothing arbitrating the collision.
Emergency change paths. Incident-time changes are made outside the normal pipeline. The immediate problem gets resolved. No post-incident remediation path exists to reconcile the change back into declared state. Not laziness — the owner who made the change during the incident was focused on recovery, and nobody was assigned to close the configuration loop afterward. That specific failure mode — an authorized exception that never gets a defined return path — is common enough to warrant its own framework: the Emergency Reconciliation Gap (#159).
Stale declared state. Configuration was accurate at commit time. Over 90 to 180 days, operational reality drifted away from it incrementally. The pipeline still passes because the declared state was never updated. The truth diverged quietly.
Automated overwrite conflicts. The remediation pipeline overwrites a change that was intentional but undocumented. The person who made the change disables the reconciliation job rather than argue about whether the pipeline’s declared state is correct. The ambiguity gets baked into the automation itself.
Each condition makes the next more likely. Ambiguous boundaries create emergency path exceptions. Emergency paths produce stale declared state. Stale state produces overwrite conflicts. By the fourth stage, the ownership model has collapsed, and the environment has normalized the failure.
Related: The Console Is the Shadow Control Plane — how manual change paths become structural authority gaps over time.
Detection Doesn’t Reduce Drift. It Increases the Surface Area of Disagreement.
When ownership is absent, adding detection tooling doesn’t reduce drift — it exposes how much of the environment’s configuration has no clear authority behind it. Every alert is now a potential dispute. Every policy violation triggers a negotiation about whether the policy applies. The tooling is surfacing a pre-existing condition. Teams often experience this as the tooling creating problems, when it is actually revealing them.
The failure mechanics follow the same structure in every case: visibility without authority produces noise amplification, not resolution.
Alerts without ownership are ignored. Not because engineers are negligent — but because acting on a drift alert unilaterally requires authority to change the resource. If that authority is ambiguous or distributed, the alert routes to a queue, the queue routes to a meeting, and the meeting produces a follow-up item that never fires. This is also where the evidence layer breaks: an alert that routes to a meeting and closes without a named resolution produces no chain-of-custody record — and a pipeline that cannot connect an execution to a specific authorization event has reached the Infrastructure Evidence Gap regardless of whether the state itself ever drifted.
Policies without ownership are disputed. The policy engine fires a violation. The team responsible argues the policy doesn’t apply to their environment, or applies differently, or was written for a configuration that predates their current state. The exception gets granted. The exception never expires. Over time, the exception list becomes a permanent configuration layer that the tooling works around rather than through.
Remediation without ownership gets disabled. The reconciliation pipeline overwrites an intentional change that was never documented as intentional. The team disables the job to stop it from overwriting their work. Now the remediation path is broken, the undocumented change is permanent, and the pipeline’s confidence signal is incorrect.
The loop is self-reinforcing — and the mechanism isn’t just operational friction. It is institutional memory decay. Trust in the tooling degrades. Exception handling becomes the default posture. Exceptions harden into permanent configuration drift. The environment’s actual state and the tooling’s model of the environment progressively diverge until they are measuring different systems.
Related: Your CI/CD Pipeline Is Your Real Infrastructure Control Plane — what happens when the pipeline owns state that nobody owns the pipeline.
What Ownership Actually Requires
Ownership isn’t a RACI entry or a team name in a wiki. It is a testable property of the system. Three conditions must hold simultaneously — and they must be held by the same named party:
- A named party can justify the current declared state without escalation
- That same party has unilateral authority to change it within policy bounds
- That same party is on-call for deviations
If any one of these conditions is missing, ownership is distributed. Distributed ownership of infrastructure state is functionally equivalent to no ownership. The drift doesn’t get resolved — it gets normalized, deferred, or suppressed until it surfaces as an incident.
Related: IDPs Don’t Solve the Ownership Problem. They Defer It. — the platform-engineering version of this same test: an IDP can automate provisioning and abstract complexity without ever assigning the three ownership conditions to a named party.
Related: Multi-Cloud Coherence Is an Ownership Problem, Not a Technology Problem — the same three-condition ownership test applied at the provider boundary instead of the resource boundary.
The conditions fail independently far more often than they fail together. The person who can explain the state doesn’t have authority to change it. The person with authority to change it doesn’t get paged when it deviates. The person who gets paged doesn’t know why the state was declared the way it was and has to escalate before acting. Each gap alone is survivable. All three failing across the same resource is how a drift event becomes a standing item on the weekly ops review that never gets closed.
Related: The Infrastructure Team Is the Real Single Point of Failure — ownership concentration and its limits in high-dependency environments.
The Signal That Ownership Is Real
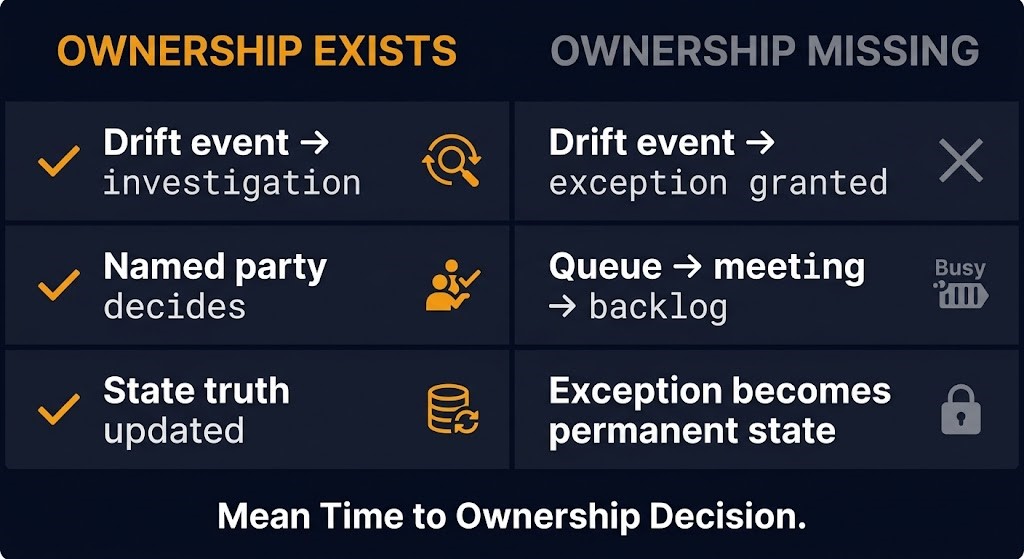
The useful distinction isn’t low-drift environments versus high-drift environments. Drift frequency is the wrong metric — it is downstream of system scale, change velocity, and team size in ways that make it nearly impossible to benchmark meaningfully across environments.
The distinction that matters is fast-resolution environments versus normalized-drift environments. Mature systems don’t reduce drift frequency. They eliminate ambiguity in response.
When ownership is real, a drift event is an anomaly that triggers an investigation: was this change intentional, who made it, and does the declared state need to be updated to reflect it? Resolution happens at the level of state truth, not just state restoration.
When ownership is missing, drift becomes background noise. Events get suppressed, filtered, or acknowledged as known exceptions that accumulate permanently. The environment’s exception backlog is the most honest measure of how degraded its ownership model is.
The metric worth tracking is mean time to ownership decision — the time between a drift event firing and a named party making an explicit call on whether the deviation is intentional or not. Observable proxies: time to identify the accountable team, number of handoffs per drift event, percentage of drift events resolved without an exception being granted. If you cannot identify the accountable party within minutes of a drift alert, the system already lacks ownership. The tooling is just making that fact legible.
Architect’s Verdict
Configuration drift ownership is the problem that the detection-remediation cycle was not designed to solve. The tooling is correct at its designed boundary. The false closure loop runs cleanly. Alerts clear, state restores, pipelines pass — and the authority vacuum that permitted the deviation is untouched on every cycle.
The failure accumulates at the ownership layer. Ambiguous authority boundaries, emergency change paths with no reconciliation loop, stale declared state, and overwrite conflicts are not independent defects — they are a progression. Each one erodes the ownership model further. By the time drift is visible as a persistent pattern, the model has usually been degraded long enough that the exceptions have become the environment.
Drift is not a detection problem. It is a question of whether anyone is responsible for the correctness of declared state. Tooling only reports the disagreement.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




